定义
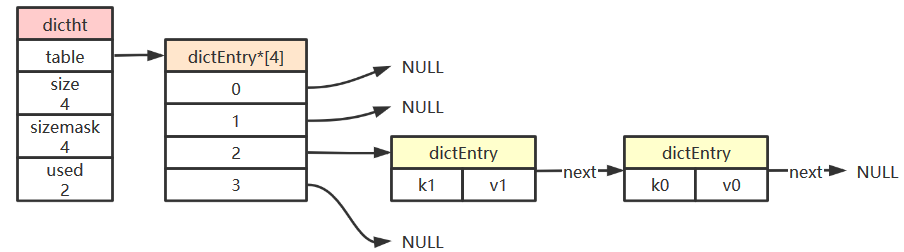
hash表
1
2
3
4
5
6
7
8
9
10
11
| typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
|
hash表节点
1
2
3
4
5
6
7
8
9
10
11
12
| typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;
} dictEntry;
|
Redis 中对hash表的实现类似于 Java 中的 HashMap。

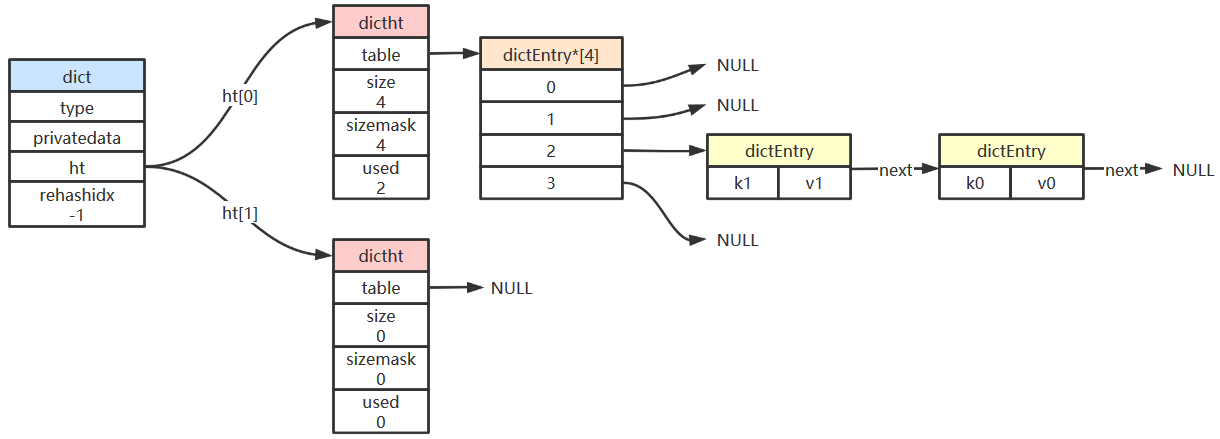
字典
1
2
3
4
5
6
7
8
9
10
11
12
13
| typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx;
int iterators;
} dict;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
|
dict.type 指向一个 dictType 结构,每个 dictType 结构保存了一组用于操作特定类型键值对的函数,Redis会为不同用途的字典设置不同的类型特定函数
dict.privatedata 则保存了需要传给那些类型特定函数的可选参数
dict.ht 是一个容量为2的hash表数组,一般来说只使用 ht[0],ht[1] 只在对 h[0] 进行 rehash 的时候使用
dict.rehashidx 记录当前 rehash 的进度,如果没有在 rehash,则为-1
以下为非扩容状态的字典结构
渐进式 rehash
由于Redis的工作线程是单线程的,因此无需像Java中的 ConcurrentHashMap 写大量复杂的代码来保证线程安全,但同时也不能像 CHM 那样实现多线程协助 rehash 来推进扩容的速度,因此使用普通的扩容方式对一个拥有庞大数量的键值对的 hash 表来扩容是一件很耗时的时间,并且会导致服务在一段时间内不可用。
为此,Redis并不是一次性地将所有的 ht[0] 的键值对全部 rehash 到 ht[1] 中,而是渐进式地将ht[0]里面的键值对慢慢地rehash到ht[1]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| int dictRehash(dict *d, int n) {
if (!dictIsRehashing(d)) return 0;
while(n--) {
dictEntry *de, *nextde;
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
assert(d->ht[0].size > (unsigned)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
de = d->ht[0].table[d->rehashidx];
while(de) {
unsigned int h;
nextde = de->next;
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
return 1;
}
|
在执行扩容期间,字典的删除、查找、更新等操作需要比较计算的数组下标和rehashidx,以此决定在 ht[0] 还是在 ht[1] 上进行操作
另外扩容期间的新增操作会直接保存到 ht[1] 中,保证 ht[0] 只减不增,随着 rehash 操作的执行最终变为空表,最后将 ht[1] 传给 ht[0]
参考:《Redis设计与实现》