应用场景
在了解什么是布隆过滤器之前,先了解布隆过滤器能做什么,有什么应用场景。
1、缓存穿透
一些用户经常访问的热点数据,我们通常将它们放进缓存(例如Redis)中,获取数据时先从缓存中获取,若缓存中不存在,则访问数据库。但是,当某些用户恶意的传递一些不会存在的数据,例如传递id=-1 或者随便传递一个UUID,这个时候数据库中没有这个数据,缓存当中自然也不存在。倘若用户连续访问,大量的请求可能会造成数据库崩溃。而通过布隆过滤器,则能够过滤掉一些不存在的数据(不能保证全部过滤),拦截掉一些恶意请求。
2、海量数据,判断给定的数据是否存在
对于判断一个数据是否存在,我们通常会想到 HashMap,但是对于大量的数据,HashMap 会占用大量的内存。这个时候可以使用 布隆过滤器 来解决这个问题,但是基于布隆过滤器本身的原理,会存在一定的误判率(如果无法接受误判率,bitMap也许是个不错的选择)。
什么是布隆过滤器
布隆过滤器的原理与 bitMap 有些类似。它实际上是一个很长的二进制向量和一系列随即映射函数。 布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。

当添加一个数据时,我们通过 k 个散列函数,将数据散列到 bit 中,并将分配到的 bit 置为 1 。例如传入一个数据a,并且通过三个不同的 hash 函数计算 a 的散列值:
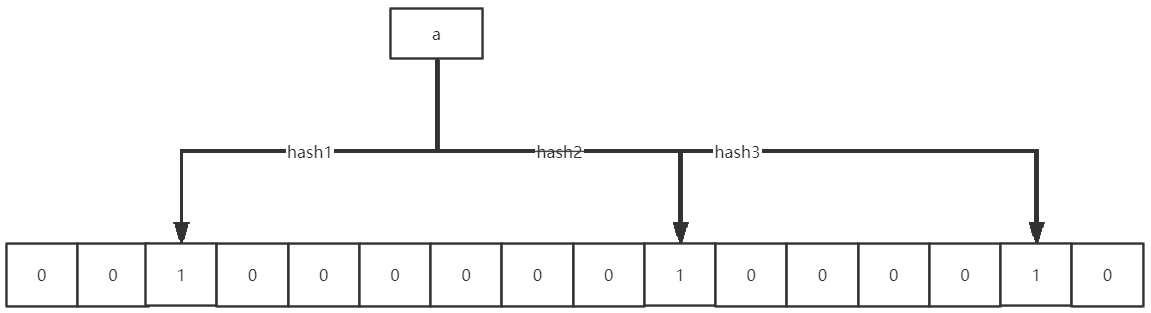
当判断一个数据是否存在时,则通过这 k 个散列函数计算散列值,如果这些散列值所对应的 bit 位都为 1 的时候,则判定这个数据可能存在。为什么说是可能存在呢,因为布隆过滤器存在一定的误判率。
当数据越来越多的时候,越来越多的 bit 位被置为 1,因此传入一个数据,判断这个数据是否存在时,可能刚好其散列值都为 1,但是这个数据却不存在。
也就是说,当布隆过滤器判定一个数据存在时,你有一定概率会被误判,但是当判定这个数据不存在时,那这个数据就一定不存在。相当于是过滤掉这些一定不存在的数据。
布隆表达式的优缺点
优点:
- 由于存放的并非完整数据,所以占用的内存相对来说少很多,并且新增和查询的速度都足够快
缺点:
- 随着数据的增加,误判率也随之增加
- 无法做到删除数据,若要实现删除数据的功能,则要添加一个计数的数组,但这样会增加内存的使用量,因此并不值得这样做
- 只能判断数据是否一定不存在,却无法判断数据是否一定存在




